
Tot allò que saben de nosaltres
Es pot navegar amb privacitat per l'oceà del 'big data'?

«L’ús d’ordinadors en la investigació sobre l’estatus financer, mèdic, mental i moral dels ciutadans és una industria gran –i creixent.» La frase sembla provenir d’algun dels textos que des de fa cert temps criden l’atenció sobre el negoci que significa la cerca i processament de dades personals. Però es va escriure fa molts anys. Es troba en el llibre Electronic nightmare. The new communications and freedom (“El malson electrònic. Les noves comunicacions i la llibertat”), publicat el 1981 per John Wicklein (Wicklein, 1981, p. 191), destacat periodista i expert en comunicació que havia estat redactor i editor en The New York Times, i que havia tingut responsabilitats en programes de notícies a diverses cadenes de televisió. La cita serveix per demostrar que el problema de la privacitat amenaçada per la informàtica i les telecomunicacions no és un tema nou. Però si el 1981 preocupava només persones ben informades com Wicklein –i molts governs–, en els últims anys la potència de les eines informàtiques i la facilitat de la transmissió de dades li han donat una nova dimensió i la preocupació s’ha estès.
A l’obra, Wicklein no només fa una exposició molt rigorosa i informada sobre els inicis de la televisió interactiva, el videotext o els diaris electrònics, debatent aspectes legals, econòmics, polítics i socials, sinó que es mostra extraordinàriament lúcid per detallar una situació hipotètica (Wicklein, 1981, p. 28–30). La situa el 1994, «quan el cable de dos sentits, interactiu, s’ha escampat a centenars de ciutats arreu del país» –en això va fer curt–. Parla d’una fictícia Martha Johnson, candidata a desbancar l’alcalde de la no menys fictícia ciutat de San Serra, al sud de Califòrnia. Aprofitant la televisió interactiva, Johnson encarrega un llibre que advoca per abolir les lleis que dificulten l’activitat sexual consentida entre adults. També compra un desodorant en esprai. Quan marxa, el seu marit fa servir el mateix aparell per respondre a un enquesta, on es mostra contrari a permetre que les lesbianes ensenyin en escoles públiques. Després, contracta una pel·lícula pornogràfica. També fa una transferència, perquè ha rebut l’avís que no poden enviar el llibre encarregat per la seva dona perquè tenen pagaments endarrerits.
«Avui, a tot el món, en un sol dia circula moltíssima informació, molta més que en qualsevol altre moment de la història»
La companyia de cable ha anat reunint informació. I té persones a qui interessa. L’alcalde i contrincant de Martha Johnson s’assabenta que el marit d’aquesta ha respost una enquesta en què mostra una opinió contrària a la que ella defensa, i que ha contractat una pel·lícula pornogràfica. Sap que ha estat ell perquè el monitor instal·lat davant la casa dels Johnson havia permès saber que la dona havia marxat i no havia tornat. Un altre client és l’editorial d’una revista porno, que envia al senyor Johnson un exemplar en un sobre discret. Un grup ecologista sap ara que la candidata compra desodorants en esprai que destrueixen la capa d’ozó. I una empresa de qualificació creditícia s’assabenta que s’ha rebutjat una compra als Johnson, cosa que inclourà en el seu dossier sobre el matrimoni.
El 1981, la hipòtesi podria semblar exagerada. El 1994 potser també, però no tant. I el 2018 veiem que, tot i ser un bon visionari, Wicklein fins i tot va fer curt.
Quanta informació circula per la xarxa i què se’n pot fer?
No sabem quanta informació circulava pel món el 1981, però només una petita part devia viatjar en format electrònic. Sí que tenim una idea aproximada de quanta informació hi havia a tot el món el 1997 gràcies a l’informàtic Michael Lesk. Va calcular que en total hi havia 12.000 petabytes (PB) d’informació (Lesk, 1997) –12 milions de gigues, per fer-ho una mica més comprensible o menys incomprensible–. Actualment, només en una hora es transmeten 500 PB, equivalents a 6.600 anys de vídeo d’alta definició. Això significa que en un sol dia ja es transmeten els 12.000 PB calculats per Lesk. Els formats són molt diversos. Cada minut s’envien uns 200 milions de correus electrònics i es pengen mig milió de comentaris a Facebook. En un dia es pengen més de setanta milions de fotos a Instagram. Afegim-hi consultes a Internet, missatges i trucades de telèfons mòbils, tuits, altres xarxes socials, imatges gravades per càmeres de vigilància, per càmeres particulars, imatges de satèl·lit, transaccions bancàries, dades clíniques… Potser no cal esbrinar si el càlcul del nombre de petabytes és força aproximat o no. La conclusió simplement és que avui, a tot el món, en un sol dia circula moltíssima informació, molta més que en qualsevol altre moment de la història.
«El problema de la privacitat amenaçada per la informàtica i les telecomunicacions no és un tema nou»
Què es pot fer amb tanta informació? Coses molt positives. I també coses molt negatives o que requereixen forts controls. Aquest gran nombre de dades i el seu processament s’anomena big data. Sovint, l’expressió no es tradueix, i quan es fa, l’equivalent és megadades o dades massives. El big data no comprèn només les dades, sinó també les eines informàtiques per processar-les. Una cosa és inútil sense l’altra.
No hi ha una definició concreta de big data. No es diu a partir de quan hi ha megadades i quan hi ha, simplement, moltes dades. En tot cas, al big data sí que se li atorguen unes característiques. Les tres V del big data assenyalen que ha de tenir volum, velocitat i varietat. La primera condició es compleix clarament, com hem vist. La segona, amb les tecnologies actuals de producció i transmissió de dades, també. I diríem que tampoc no cal estendre’s a justificar la tercera. Sovint s’hi afegeixen dues V més: veracitat i valor. Cal que les dades siguin fiables, cosa que no sempre es produeix. I cal que tinguin valor, i això darrer és més fàcil de demostrar.
Així, el big data té una gran importància en els àmbits més diversos. Qualsevol camp on calgui tenir moltes dades i processar-les es beneficia de les tècniques de big data. Ordinadors potents augmenten la velocitat de càlcul i algoritmes complexos permeten transformar les dades en informació útil. Les dades poden ser molt científiques –interaccions entre partícules en un accelerador, posicions i dades astrofísiques d’estels i galàxies…– o molt quotidianes –la gestió del trànsit o del servei de neteja en una ciutat–. Tots els àmbits de la recerca es beneficien de les megadades. Un estudi sobre les mutacions genètiques que es donen en un cert tipus de càncer i que no apareixen en pacients sans, relacionades també amb estils de vida i altres característiques de cada persona, no es podria fer sense el big data i sense un supercomputador. Els estudis climàtics serien molt menys útils si no poguéssim processar amb certa velocitat immenses quantitats de dades.
Dades que proporcionem sense saber-ho
Però les dades tenen valor en molts àmbits més, i no sempre es coneix qui les fa servir, com i per a què. Si amb una tecnologia encara limitada i poc estesa Wicklein imaginava aquell perjudici per als Johnson, imaginem què es pot saber avui de nosaltres.
Es poden esbrinar coses sobre nosaltres a partir de dades que proporcionem alegrement i de forma voluntària. La majoria fa cerques a Internet amb buscadors que preserven les dades del que hem buscat i quines webs hem visitat –són les anomenades cookies–, reenviem tuits que poden ser vistos per milions de persones i que poden quedar enregistrats, pengem comentaris a Facebook o fotos a Instragram. No tothom fa tot això ni molt sovint, però en tot cas són dades que lliurem per poder tenir o proporcionar informació, per comentar coses o per pura moda o narcisisme. Un consell és ser discret i caut. Però, com veurem més endavant, això no és suficient. L’ús que va fer la consultora Cambridge Analytics dels perfils de 87 milions d’usuaris de Facebook és un bon exemple que no sabem on va a parar la informació sobre nosaltres.
L’any 2015 uns investigadors varen voler crear un algoritme que pogués jutjar la nostra personalitat a través del rastre que deixem a Facebook (Youyou, Kosinski i Stilwell, 2015). Ho van comparar amb uns qüestionaris omplerts per companys, amics, parelles i familiars. I van veure que basant-se només en deu «M’agrada», l’algoritme coneixia l’usuari tan bé com un company de feina. Amb 70 «M’agrada», ja era tan precís com ho podia ser un company d’habitació. Amb 150, ja el coneixia tan bé com un progenitor o un germà. I amb 300 era tan exacte com ho podia ser la seva parella. Només amb això, amb una petita part del rastre que deixem a Internet, ja se’n pot elaborar un perfil amb força aproximació.
«Qualsevol camp on calgui tenir moltes dades i processar-les es beneficia de les tècniques de big data»
Potser això sembla poc important comparat amb un estudi anterior (Kosinski, Stilwell i Graepei, 2013) on s’havia demostrat la capacitat d’aquests algoritmes per endevinar altres coses. Fet amb més de 58.000 voluntaris, va permetre constatar que l’algoritme era capaç de predir, en un 88 % dels casos, si l’usuari era heterosexual o homosexual, en un 95 % si era afroamericà o caucàsic, en un 85 % si era republicà o demòcrata, en un 82 % si era cristià o musulmà. Fins i tot es van creure capaços d’encertar en un 78 % dels casos si era intel·ligent i en un 68 % si era emocionalment inestable.
Quan s’alerta sobre les amenaces a la privacitat, molta gent addueix que rebre publicitat o propostes comercials no és un problema greu. Diuen que pots fer-ne cas o no i ja està. És possible, tot i que pot arribar a ser una mica carregós. Però amb les dades massives ja no es tracta d’això, sinó d’informació molt més sensible i que tothom té dret a mantenir en secret si ho desitja, com la ideologia, la religió o les preferències sexuals. Hi ha països on l’homosexualitat és delicte i pot significar fins i tot una condemna a mort. Que un algoritme pugui predir si una persona és homosexual no és innocent ni innocu, i el mateix passa amb la religió o amb les opinions polítiques o l’activisme social.
Informació per a mútues, asseguradores, empreses…
Hi ha moltes coses més que es poden deduir de les nostres dades que no afecten només un col·lectiu, com l’homosexual. Tots generem d’una manera o altra informació mèdica. Ja no es tracta de tot allò que tenen de nosaltres en els seus arxius metges i hospitals i que en cert moment pot ser robat per ciberdelinqüents. Hi ha altres possibilitats. Si fem una cerca sobre una malaltia determinada, Google sap que ho hem fet. Si comprem un llibre sobre certa malaltia, Amazon sap que ho hem fet. Si opinem sobre determinat trastorn o busquem gent que el pateix o famílies de gent que el pateix, Internet ho sap.

Aquesta informació que circula i que algú conserva, relacionada amb moltes informacions més sobre les nostres activitats, pot fer creure a un algoritme que tenim la malaltia o que ens preocupa poder-la tenir en el futur. Potser simplement ho busquem per curiositat o per altres raons. Però si la informació arriba –i pot arribar-hi perfectament– a asseguradores o mútues, podem tenir problemes per subscriure pòlisses o assegurances de vida. I si arriba a empreses en general, poden tenir molta informació sobre els possibles problemes mèdics d’un candidat a un lloc de treball. Hi ha empreses que acumulen dades mèdiques i no mèdiques de milions de persones i que les utilitzen per acceptar o denegar una sol·licitud d’assistència mèdica (Allen, 2018). Utilitzen algoritmes que no són infal·libles.
Un algoritme és un seguit d’instruccions ordenades que permeten afrontar un determinat problema o operació. N’hi ha de molt senzills, com el que permet comprovar si hem fet bé una divisió: quocient per divisor més residu ha de donar el dividend. N’hi ha de molt complexos, que tenen centenars de línies de codis informàtics. El cercador de Google deu tenir uns milers de milions de línies de codi.
Els algoritmes no pensen. Els algoritmes segueixen instruccions i assimilen dades. Però algú ha d’haver-los dit quines dades han d’assimilar. Les dades les trobaran a la xarxa o en arxius o publicacions que reflecteixen aproximadament el que és la societat (Duran, 2018, p. 147–165). Els dissenyen i elaboren persones i tenen els tics dels que els elaboren. Aprenen a partir de la informació que se’ls proporciona o que un sistema intel·ligent pot recollir. No entenen de matisos si no se’ls entrena perquè els tinguin en compte, i per això poden arribar a conclusions curioses (en podeu veure uns quants exemples a O’Neil, 2016/2018).
A més, molts algoritmes no estan validats. I les empreses els solen amagar perquè consideren que són una propietat intel·lectual que cal preservar de la competència. El resultat és que són caixes negres (Pasquale, 2015) on se’ns jutja pel que diuen les nostres dades i no amb una certesa absoluta, sinó simplement amb probabilitats. Jutgen la nostra possible despesa mèdica segons el barri on vivim, els estudis dels nostres pares o les nostres amistats i els comentaris que aquestes fan. No som individus, sinó estadístiques processades. I sobre això es prenen decisions vitals.
Del rostre als gens
Les possibilitats del big data per aportar coses positives creixen cada dia. Hi ha recerques en els àmbits més diversos que fan progressar la ciència i la gestió de l’àmbit públic o que ens poden fer la vida més fàcil. Però també augmenten les possibilitats tant de captar dades sense que ho sapiguem com d’aplicar-les amb intencions poc clares que, a més, desconeixem. I el desconeixement causa indefensió.
«Només amb una petita part del rastre que deixem a internet, ja se’n pot elaborar un perfil amb força aproximació»
Així, els sistemes de reconeixement de rostres són cada cop més precisos: poden identificar gent en fotos o vídeos –gent que potser no vol ser identificada– i relacionar el rostre i el nom amb altres informacions que es troben a la xarxa. De vegades, no calen ni aquests sistemes. Facebook demana als usuaris que etiquetin la gent que coneguin que apareix a les imatges. Ja no cal ni fer servir Facebook per estar etiquetat a Facebook! Hi ha sistemes que poden identificar, a partir de la veu i el discurs, si una persona presenta senyals de Parkinson o Alzheimer, fins i tot abans que sigui possible un diagnòstic mèdic. Això és molt positiu per aplicar la prevenció o el diagnòstic precoç, però ho és menys si hi ha empreses que ho fan servir per esbrinar si algun treballador –o algú que vol contractar una pòlissa– presentarà aquests símptomes en un futur més o menys proper.
La genètica afegeix una dimensió més a les possibilitats i als riscos. Aquesta ciència ha avançat molt, però això, a més de fer conèixer molts gens lligats a malalties o a la predisposició a patir-les, també ha permès constatar la seva gran complexitat. Ja no cal tenir en compte només els gens, sinó també l’epigenètica, és a dir, les alteracions que poden afectar l’expressió dels gens a causa de l’alimentació, la contaminació o traumes vitals i que fins i tot es poden transmetre a la descendència.
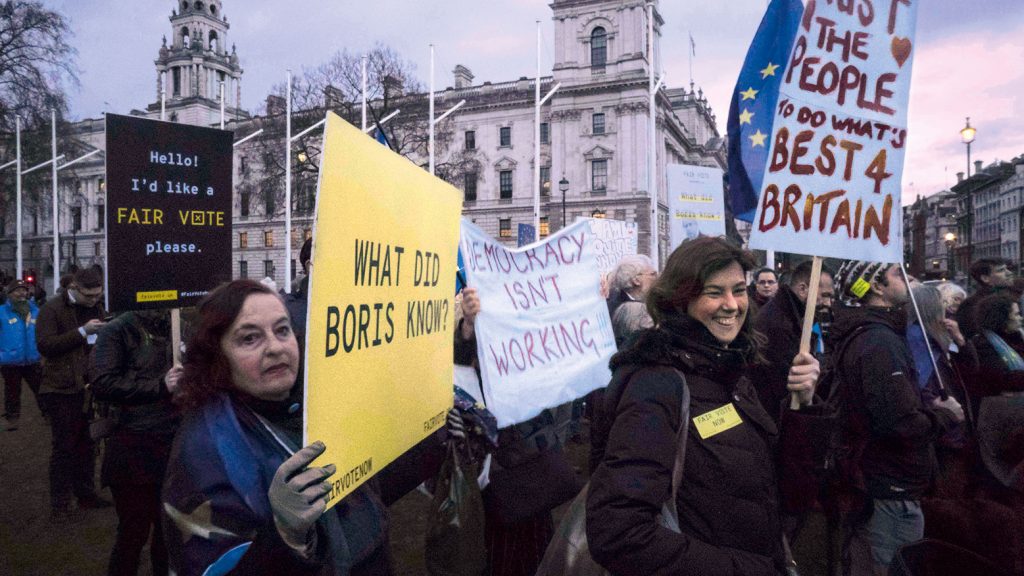
L’accés a informació sensible d’usuaris per part de terceres parts interessades és un tema candent. A començament de 2018, esclatava l’escàndol de Cambridge Analytica, quan es va descobrir que aquesta consultora britànica havia utilitzat informació de 87 milions d’usuaris de Facebook per a elaborar missatges publicitaris personalitzats –fins i tot fake news– favorables a la victòria de Donald Trump en la campanya electoral nord-americana de 2016. Immediatament, el paper de Cambridge Analytica en altres campanyes electorals va ser sotmès a escrutini públic. Els lligams entre la consultora i el sector del Vote Leave (“vota marxar”) en el referèndum celebrat en 2016 al Regne Unit sobre la permanència del país a la Unió Europa van fer que molts ciutadans eixiren al carrer per a protestar pel que consideraven un procés manipulat. / John Lubbock
Per això, alguns gens determinen, però n’hi ha molts més que no. Que es pugui cedir informació genètica presenta un risc segons en quines mans caigui. Però, a més, afecta el nostre entorn familiar. Podem evitar que hi hagi dades nostres en arxius, però si un parent directe les ha proporcionades, està oferint també una part de la nostra identitat genètica. I ara no és tan difícil que algú ho faci. Empreses com 23andMe ofereixen proves genètiques per conèixer la predisposició a certes malalties o per buscar, en la seva immensa base de dades, possibles parents més o menys directes.
Conclusions
Des que el 1895 Wilhelm Röntgen va descobrir els raigs X i va obrir el camí a la radiologia, el nostre cos no ha deixat de fer-se cada cop més transparent (Duran, 2016). I el big data ha aconseguit que no només sigui transparent el cos, sinó també els nostres actes i pensaments. Això genera possibilitats immenses, però també molts riscos (Duran, 2018).
No n’hi ha prou amb la prudència dels usuaris –que també és imprescindible– per evitar aquests perills. Per això, hi ha d’haver una legislació que protegeixi els seus drets i uns tecnòlegs i unes empreses que comprenguin la necessitat de posar límits a les eines informàtiques. El Reglament europeu de protecció de dades, obligatori a tota la Unió des de maig del 2018, pretén garantir que tothom pugui triar quines dades dona, a qui i amb quin objectiu. I que pugui fins i tot reclamar que se li expliqui quins criteris ha tingut en compte un algoritme que hagi ajudat a prendre una decisió –sobre un crèdit, una feina, un contenciós…
Aquests drets són un element essencial. Però també ho és estudiar bé allò que es desprèn dels models matemàtics per no obtenir conclusions esbiaixades que condicionen el present i el futur. Poden ser eines potents per fer una societat més justa, sempre que estiguem disposats no només a cantar les seves excel·lències sinó també a admetre i contrarestar les seves limitacions. Com deia en un article Joshua Blumenstock (2018), director del Data-Intensive Development Lab i professor de la Universitat de Califòrnia a Berkeley, l’ús del big data per al desenvolupament ofereix moltes possibilitats, però requereix una versió de la ciència de dades «considerablement més humil que la que ha captat la imaginació popular». La humilitat és sovint necessària per assolir l’èxit, perquè ajuda a corregir o evitar errors. Per això, caldrà incloure-la i exercitar-la en l’algoritme que ens ha de dur a la societat de dades del futur.




